Actuarial Studies is more than maths #
Consider this: (
source)
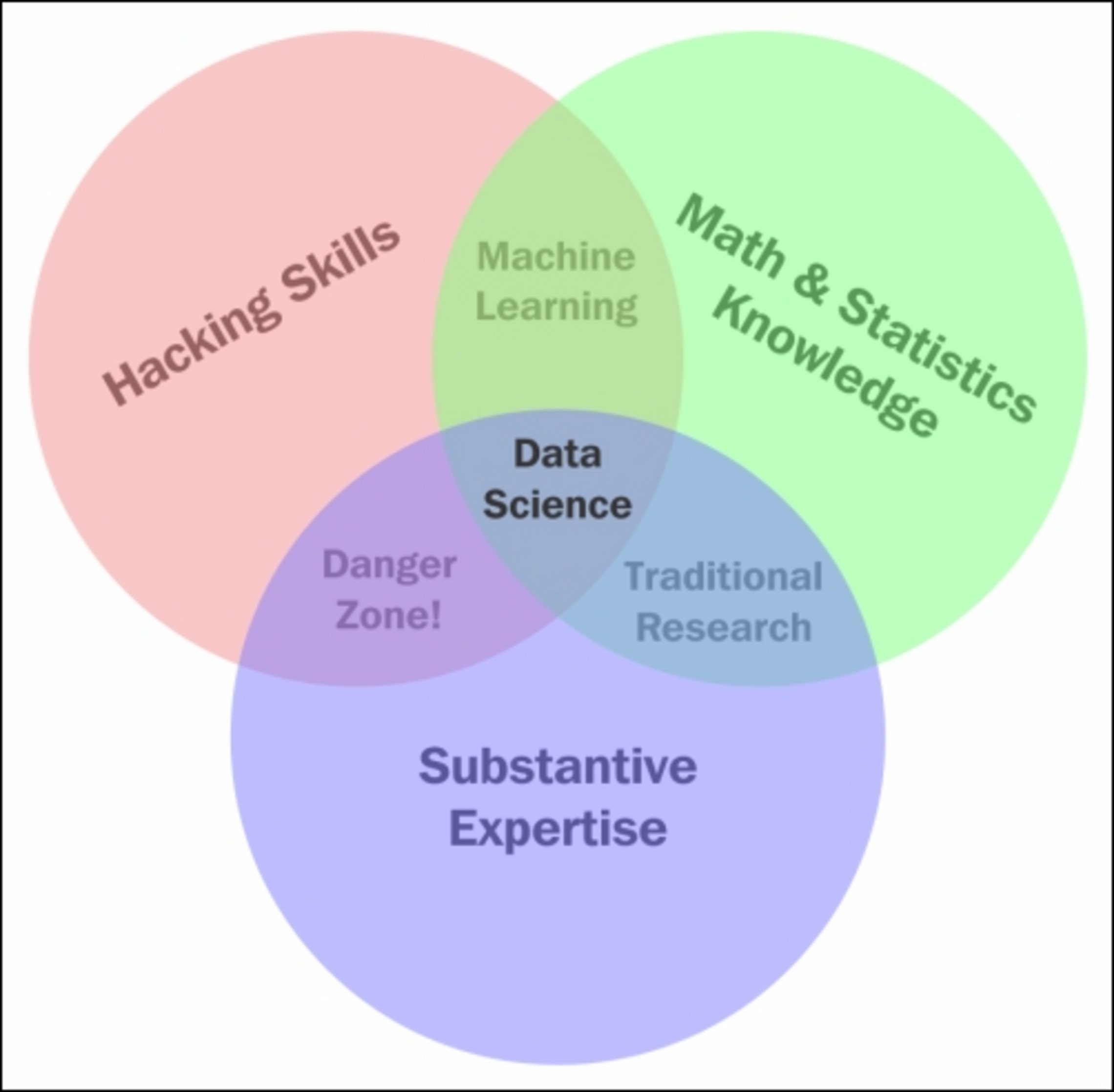
- In the Venn diagram, you would replace “Substantive Expertise” with “Business knowledge,” and you would be pretty close to what actuarial studies is (in the middle)
- People will have different forte’s, but a good (modern) actuary has basic knowledge in all three dimensions, and can help with the communication between those functions
- In fact, actuaries have been doing that kind of work for a very long time, even before the so-called “big data” revolution
- Actuaries are not the only ones who can add value in data analytics (for predictions in particular), but they have a long history of it
AD: “Finding the Data Analytics Unicorn” #
Some quotes #
Finding the Data Analytics Unicorn is an older article which is still quite relevant:
- “there are now new data sources and new techniques available.”
- “discussion about how difficult it is to find someone with . Chris Dolman identified this individual as the”Data Analytics unicorn" and suggested that when that right combination can’t be found in a single individual, you need to create a team to meet all of these needs"
Chris Dolman on his career #
Challenges #
- “Working in the area of Data Analytics, you will sometimes find yourself `locking horns’ with business teams who aren’t used to, or comfortable with, working in new ways.”
- “Daniel Marlay (Ernst & Young) highlighted some of the communication challenges, including the need to explain experimentation to non-scientists, the importance of knowing who your audience is and providing either an outcome focus to senior management or using a narrative style with lots of detail for more technical audiences.”
- look at fun examples!
Modelling culture and AI #
What are we trying to do? #
Consider outputs ( \(y\) ) from inputs ( \(\mathbf{x}\) ) in nature:

Statistical modelling tries to “model” nature in order to reach two types of conclusions from data ( \(\mathbf{x}\) ) (Breiman 2001) :
- Prediction: predict
\(y\)from future sets of\(\mathbf{x}\) - Information (or inference): extract information about the association of
\(y\)and\(\mathbf{x}\)- understand nature
Artificial intelligence #
Some vocabulary:
- Artificial Intelligence: smart (intelligent) stuff performed by a computer
- Machine learning is a subset: here the program “learns” to perform a given task better (according to some success criteria) as more data is fed to it
- Deep learning is a subsubset: usually refers to “deep artificial neural networks.” Such networks have a certain number of layers, leading to the idea of depth.
- Machine learning is a subset: here the program “learns” to perform a given task better (according to some success criteria) as more data is fed to it
$$\text{deep learning} \subset \text{machine learning} \subset \text{AI}$$
Modelling cultures #
Breiman (2001) distinguishes two modelling cultures:
- data modelling culture
- algorithmic modelling culture
This distinction helps work out the main differences between traditional statistical models, and the newer ones included in AI.
Data modelling culture #
Here we assume that the data is generated from an underlying stochastic model which is explicit:

- We have
$$ y = f(\mathbf{x}),$$
where
\(f\)needs to be chosen and is relatively inflexible - This is the older, traditional approach
- The model will be as good as the choice of
\(f\), and might be very “precisely wrong” (as opposed to “approximately right”)
Algorithmic modelling culture #
Here the mechanism by which data is generated is considered as unkown, and is modelled with algorithmic approaches:

- This has no (or less) explicit structure and has perhaps better chances of modelling “nature’s processes”
- It is the newer, “machine learning approach,” which is more organic
- It thrives with more data and computing resources
- It is also harder to interpret (and communicate) as the middle is more of a “black box”
Impact of Big Data on the Australian insurance industry #
Some quotes #
Actuaries Institute says Big Data set to transform Australia's insurance industry
- Green Paper on how Big Data is transforming the insurance industry and the implications for the cost and availability of insurance for all consumers.
- “Improved data will produce winners and losers amongst insurance customers”
- “Insurers that choose not to use available data will end up in the unsustainable position of only insuring the higher risks. Hence big data usage is likely to become widely adopted.”
-
“The good news is that many consumers will benefit from this new technology. Premium pricing will more accurately reflect risk behaviour – good young drivers will pay less than risky young drivers (or risky older drivers),” the report said.
-
“However, there will be a smaller group of consumers who will have to pay more for insurance because they are considered higher risk, even though they may not be able to control the risk they seek to insure,” it said.
Analysis #
Headlines #
Let’s analyse the headlines:
- “Many consumers will benefit through lower premiums, insurers will be able to provide more accurately priced products.”
- “Increased use of data raises issues of insurance access and affordability.”
- “Privacy and discrimination issues will be of increased concern.”
Adverse selection #
Risk factor identification forces competitors to follow:
- If Insurer A differentiates with respect to one (significant) risk factor, but not Insurer B, all “good” risk will move from Insurer B to A, and all “bad” risks will move from Insurer A to Insurer B.
Discussion: precision vs mutuality #
-
The insurance business is the business of risk diversification
-
More precise pricing leads to less mutuality
- What are the pros and cons here?
- What if the factor is in or outside control of the policyholder? (Smoking? Genetics? Address? Income?)
- What factors are unacceptable to consider? (illegal, unethical)
-
Lack of access to insurance due to unaffordability (Do people have a right to access insurance? What can be done if they can’t?)
-
Including a risk factor that the policyholder has control on may reduce risk
Privacy and discrimination #
- Privacy issues
- Who owns the data?
- How can it be used?
- Discrimination issues
- Is this fair? How do we determine fair?
- What unintended consequences might there be?
- Direct vs Indirect Discrimination
- Non mandatory optional reading:
Should I Use this Rating Factor? Philosophical Approach to an Old Question
Insurtech #
- Loosely speaking, “Insurtech” refers to the use of technology for insurance
-
Insurtech trends: using data to create dynamic insurance- a lot of data can be gathered, which can improve the risk assessment and pricing (underwriting)
- moreover, this could be done in a dynamic way
- we are back in the precision vs mutuality issue, and there are ethical issues, too
-
New insurtech FloodMapp could save insurers millions in claims assessment costs: another example
Further resources (non mandatory) #
-
Actuaries in Data Analytics (Practice Committee) -
Podcast - What is machine learning? -
Podcast - Chris Dolman interview on Ethical AI -
Let’s stop talking about “risks of AI bias”, and instead start deciding what we want the world to look like -
The Discriminating (Pricing) Actuary
References #
Breiman, Leo. 2001. “Statistical Modeling: The Two Cultures.” Statistical Science 16 (3): 199–231.